When you work with Big databases with many records and not uniform distribution of data into columns used for join or where conditions, you can have really bad performance problem due to Query Plan caching. I do not want to give a deep explanation of this problem, you can find information here, but I want to outline the general problem to make clear what is happening.
We can argue a lot why this problem happens in a database engine, but basically I have a really bad situation where the db stores data of multiple customers with really non uniform distribution of data (some of them have ~1000 rows for each table, others have ~100.000 rows in some of the tables).
The problem is the following one : the software issue a query (two tables in join) filtered with a customer Id that has few rows on these tables; SQL-Server creates a plan where tables are joined with nested loops and the query executes in 2 milliseconds.
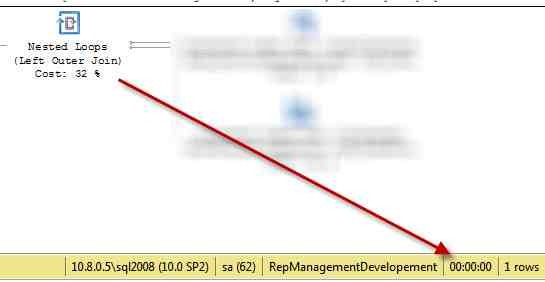
Figure 1: Query with a value of parameter that filters for a customer that has ~100 rows in the two tables used in the join (elapsed time = 2ms).
As you can see the execution time is almost zero, now I execute the very same query, changing the value of the parameter to filter records for a customer that has nearly 100.000 records, since the query is the same, sql server uses the same execution plan.
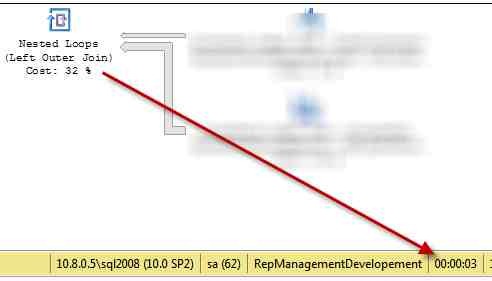
Figure 2: Query gets executed filtering for a customer that has ~100.000 rows in the two table that joins together (elapsed time = 2824 ms).
The query is three order of magnitude slower (2.824 ms vs 2 ms) and for query that are more complex (three tables in join), sometimes the execution time is more than 5 minutes and the software gives a TimeoutException. As you can see from Figure 2 , the gray arrow from the bottom table is really wider respect of the arrows of Figure 1 , because this customer has more rows in database. If you issue a DBCC FREEPROCCACHE command toclear all cached query plans and execute again the query of Figure 2, you got an execution time of 28 ms (100 times faster than before XD).

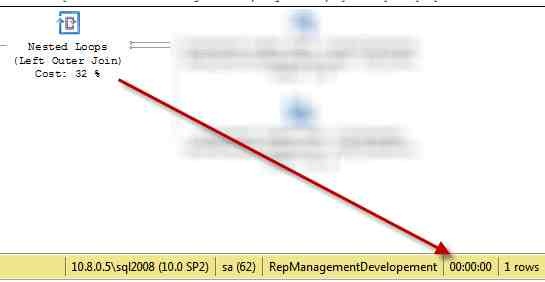
Figure 3: Join is done with an hash match, a technique that is more efficient for joining two tables with a lot of rows. (elapsed time = 28 ms).
In figure 3 you can see that if you clear the query plan cache and execute again the query, SQL Server check the table, and since this customer has a lot of rows it uses HASH MATCH join and not a nested loop. Now if you execute the query for the customer used in Figure 1 that has few rows, the execution time is 28 ms, higher than 2 ms because an hash match is less efficient for few rows.
This lead to a nasty problem due to order of execution of the query : if I issue the same query, first for the customer with a lot of rows and then for the customer with few rows, I got an execution time of 28 ms for each query, if I reverse the order of the query I got 2 ms and 2800 ms thus the system is much slower. This happens because the Hash Match is not good for few number of rows, (28 ms against 2 ms), but the loss of performance when we have a small set of record is not so bad; at the contrary, the Nested Loop is a KILLER for big resultset and this can even cause execution Timeout. Having such a problem in production is like sitting on a bomb ready to explode. (A customer calls telling us that the software is completely unresponsive, you verify that this is true, but for other customers everything is quite good :(

{kind=link}
{kind=link}
{kind=link}
{kind=link}
The only solution to this approach is using the OPTION (NORECOMPILE) for all queries that present this problem, or you can instruct the query governor to prefer some join option (using OPTION (HASH JOIN) for example) if you already know that this is the right execution plan for all data distribution. All these techniques are called** **** query hint ** and are the only way to solve bad performance problem of parameterized query when you have non uniform data distribution.
Now the problem seems solved, but, wait!!!!!,** most of the queries are issued by nhibernate **, and I need to find a way to add query hints to nhibernate query, a task that is not supported natively by NH. Solving this problem is a two phase process, first of all you need to find a way to insert text into nhibernate generated SQL, a task that can easily solved by an interceptor.
| |
As you can see the code is really simple, the interceptor inherits from EmptyInterceptor and override the OnPrepareStatement(),** adding the right Query Hint to the end of the query **. This is probably not 100% production ready code, because I’m not 100% sure that for complex query, inserting the hint at the end of the query is the right choice, but for my specific problem is enough and it is a good starting point.
If you look at the code you can verify that I’m checking for certain string in query text to add the appropriate hint, but how can you add these strings to the query to enable query hint to be generated? The answer is comments. First of all I add this interceptor to NH configuration, so it got attached to every session.
| |
But I also enable comments in SQL code in NH configuration setting the property** use_sql_comments **to true, now I only need a couple of extension methods like this one.
| |
That enables me to write this HQL query.
| |
As you can see I have now the QueryHintRecompile() method that permits me to specify for each single HQL Query (you can add similar extension method to ICriteria) the query hint to use. Running this query output this query.
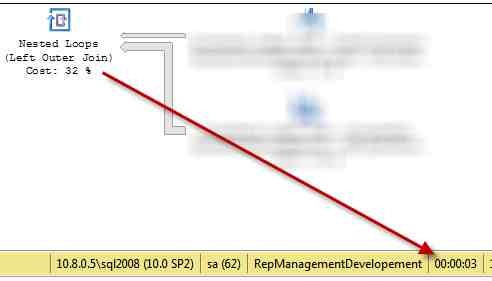
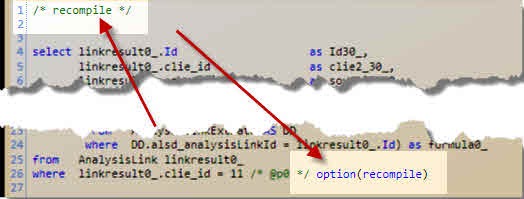 ** Figure 4:**The query with the query hint specified by the QueryHintRecompile()
** Figure 4:**The query with the query hint specified by the QueryHintRecompile()
{kind=link}
Thanks to incredible number of extension points offered by NHibernate, adding Query Hint to queries is really a breeze.
Alk.
Tags: NHibernate Sql Server