Part 1: First Steps
Part 2: Managing Relations
Part 3: Collection Relations
In the first three parts of this little tutorial I showed how easy is to save objects to database with EF 4.1 code first approach, now it is time to understand how to retrieve objects from the database.
Querying objects from database is really easy in EF, because you have full LINQ support; as an example suppose you want to retrieve all warriors with a name that contains a particular search string.
| |
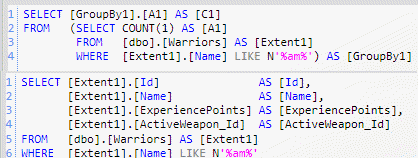
Ad you can see you are expressing the query against the object model, you are in fact asking for all warriors whose name Contains the string (am). If you analyze the LINQ query you can notice that I used the method System.String::Contains but Entity Framework Profiler shows the real query issued to the database.
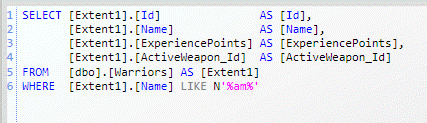
Figure 1: The query issued to the database intercepted by Entity Framework Profiler.
This is the real power of LINQ: the original query expressed in terms of Object model gets analyzed from the EF LINQ provider and translated to the equivalent SQL syntax, another interesting feature is that the query returns objects, not a DataReader or some Database related structure. Now look at this other piece of code.
| |
This code is really similar to the previous one, but with the only difference that I’m not using ToList() method in the query, instead the result is stored into a IQueryable<Warrior> object. Once the query is created I iterate two times the IQueryable object and the result is that *the same query is issued two times to the database *. To understand why you need to understand the difference from a Deferred and Non-Deferred operator in LINQ.
In the above example the Where operator, used to specify the criteria for object retrieval is a * Deferred Operator *, this means that the operator gets executed only when we iterate through its content. This is why each time you iterate the IQueryable<T> object another query gets issued to the database. To avoid this you can call ToList() * non-deferred operator *, that executes immediately the LINQ query, returning all objects inside a List<T> object; now objects are in memory and you can iterate the list how many time you want without issuing further queries to the database.
This is a really interesting concept that you can use for your advantage, like in the following example.
| |
This piece of code creates a IQueryable<T> that filters all warrior whose name contains the am string, then print the number of warriors that satisfy that criteria (line 6), and then iterate through all records to print details. This piece of code actually creates two queries to the database.
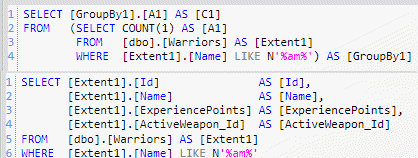
Figure 2: The two queries issued by the previous snippet of code
The interesting aspect is that the first query actually issue a select COUNT to the database, it does not load all objects. Suppose that you need to do server side pagination, loading three warriors for each iteration.
| |
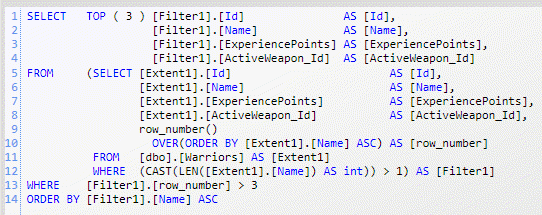
This time the query on line 3 has an order clause because you cannot use server side paging without ordering, then I issue a *Count()*query (line 7) to know all records that satisfy the condition, then I begin a cycle to load a page at a time, since I know the total number of records. Thanks to Skip and Take operators loading objects a page at a time is really super simple. Here is the output of the above snippet.
| |
Being able to load object with server side pagination can tremendously increase the speed of programs; in this example I load all objects a page at a time, but in real situation you load the first page, show the result to the user and shows other pages only when the user ask explicitly to view data for another page.
The above piece of code issues three queries to the database, the first one is a simple count, the other two are more complex, because they should implement server-side pagination.
{kind=link}
{kind=link}
{kind=link}
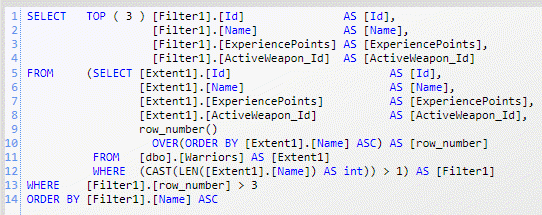
Figure 3: The query that loads the second page of the records
Actually you could create a more readable query if you hand-code server side pagination, but being able to do this with Skip() and Take(), makes possible even for a Sql Server novice developer to write efficient, but simple code.
Alk.
Tags: Entity Framework