Configuring a build to build each commit to constantly verify quality of code is usually a good idea, but sooner or after, in big solutions, you start filling pipeline queue. The main problem is that, when the team grows, the number of commits for each day of work increase and you start having problem in build queue. If build queue is more than one hour long, it is still acceptable, but if the queue is even more, it become clear that you should find a solution.
If your pipeline starts accumulating run in queue, the simplest solution is to throw more pipeline license and hardware in the pool
Even if you think that throwing hardware is a coward solution, usually it is the best approach. The real problem is that, sometimes, lots of time is wasted in unnecessary work. Let’s get a typical situation, I have a build that compiles a big .NET solution and executes test in a job, then I have another job devoted to some Jest Angular Test. Most of the builds were triggered by a change that happens only in Angular solution or in .NET solution, but both jobs are executed. Ok, you can now argue that creating two distinct pipeline solves the problem, because you can apply condition to trigger, but in my situation I really like to have a single pipeline that verify everything.
I really prefer having a single pipeline that does multiple job, it is simpler for the team.
If you have a single pipeline there is a single point where the team will look for problem in the code, while having multiple pipeline disperse the attention.
My problem is that you cannot setup source filter trigger for single job, you can for the entire pipeline, but then you cannot tie execution of a job to a change in some path. Luckily enough you can use another approach: create a first job that analyze the changeset, find changed files and populate pipeline variables that can be used from dependent job to determine if the job should run. With this solution I can leave the trigger alone, triggering a build for each commit in each branch, but I have a first job that quickly determines which other jobs should run.
In this scenario I have to run job for Angular solution if something changes inside src/frontend/Jarvis.UI folder, and conversely run .NET job only if something is changed in src/ folder but not in src/frontend/Jarvis.UI (we have wiki/ asset/ and other folder not related to .NET code and when someone changes the wiki a full build is triggered).
In following figure you can see the net result: I’ve committed a small change in .NET part of the project, as you can see only .NET related work is really executed.
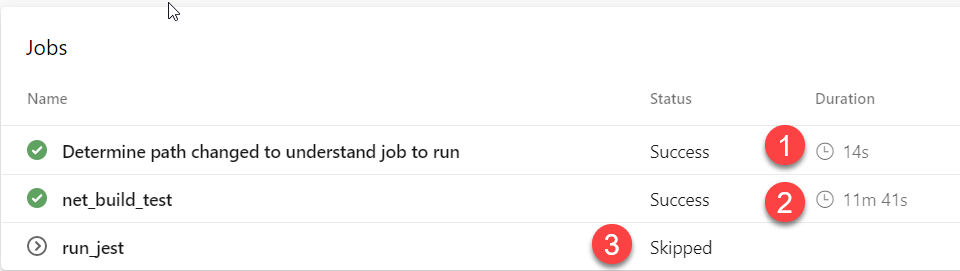 Figure 1: Conditional job in action, only .NET job is executed if I didn’t change code in UI part of the solution
Figure 1: Conditional job in action, only .NET job is executed if I didn’t change code in UI part of the solution
As you can see in Figure 1 I spent 14 seconds in the first extra job, but I gain a big advantage due to the fact that run_jest job was skipped because there are no change related to angular solution. As you can see, running all the tests in the solution occupy something like 12 minutes, so if someone changes something in the UI, I save a huge amount of time.
Avoiding running entire jobs depending on what really changed from the previous commit is a real time saving.
Now you can ask how complex is to obtain this result, but the reality is that it is just a matter of some PowerShell code as for the following example.
| |
Thanks to this simple PowerShell snippet, I use git commandline to get a list of all files modified in actual commit, then with a couple of RegEx I can determine if some file changed in Angular UI and other changed in .NET project. Based on that fact I set a couple of variables (lines 21 and 24) called JobNet and JobUI. Pay attention to use the isOutput=true when setting the variable, because you need to use them in other job.
Now it is time to put this script in a job inside the pipeline.
| |
It is of uttermost importance that you give a name to the job (determine_changes), then you also need to give a name to PowerShell step (files_changed) because you need those two information to use in condition for subsequent jobs.
After this first job, here is how you need to declare other jobs to use previous variables to determine if the job is to be run.
| |
As you can see in Line 4, you can declare variables referencing output variables of other jobs, that allows you to use JobNet variable to set a condition for job execution. As a recap you nee
- Create a job that determines changed files and set variables accordingly
- Give that job and the step that output variable a name
- Create other job that depends on the previous job
- Use dependency syntax to reference variable of previous job
- Use that variable as condition for the job.
And the game is done, each commit will trigger a build, first job will determine what to build and other job executes accordingly.
Gian Maria.