Nhibernate supports lazy loading for single properties and this solves perfectly the situation where a table has on or more field with a lot of data and you absolutely need to avoid loading all that data each time you load the entity. Basically with NH you can define Lazy Properties and the content of that property is loaded from the database only if you access it.
Entity framework does not supports this feature, but it can solve this scenario with Table Splitting, as described by Julie Lerman. The problem is that the example by Julie is based on EF designer, but I want to use Code First. In this post I’ll describe you the steps I did to move from a standard Entity mapped on a single table to Two entity mapped to the same table with Table Splitting with a Code First approach.
My scenario is: I have a table with a column that contains really lot of text data that is used rarely. The entity mapped on that table is used basically on every action of most of the controllers in a asp.NET web application. The overall performance is degraded, because each time more than 1 MB of data is loaded into memory, only to read a bunch of other values of that table. The database should not be refactored and we should find a solution to load the big text data only in the rare situation where it is really needed.
This is the original EntityA properties: Id, Name, Surname, BigData properties, where BigData contains lots of text rarely needed.
| |
The solution to the problem is Table Splitting or mapping two distinct entities on the same table. The “master” entity maps all standard fields of the table, the other one maps data that are rarely needed (BigData in this example). These are the final entities.
| |
The key points are: they have both same Id property , EntityA has a reference to the EntityAPayloadMap to estabilish a 1:1 relation and finally all properties are virtual to enable Lazy Loading. It can sound weird, but the 1:1 relation is mandatory and also is clearer to comprehend. If you map two unrelated entities on the very same table, EF will gave you an error telling that you should establish a relation. This limitation is not a problem for me, because I do not like the “unrelated entities” approach, after all the Payload is part of EntityA, it has no sense without an EntityA, and I only want the loading to be done only when needed. Mapping those two is really simple.
| |
You should have the same Id, this means that the two class should have an Id property mapping to the same column of the table and they should point to the same table. Then it is mandatory that EntityA has a 1:1 relationship with the payload, estabilished by the HasRequired().WithRequiredPrincipal. This is everything you need to do to enable Table Splitting, but you should be aware of a couple of issues that gave me a little headache.
You are not able to save an instance of EntityA if it has Payload property set to null, the relationship is mandatory and you cannot avoid populating it. This lead naturally to a simple solution: populate the Payload property on the constructor (or lazy initialize in the getter) so you will never have an EntityA without a Payload. The net result is that you cannot load the payload anymore. Suppose you initialize Payload in the constructor to make sure that each EntityA always have a Payload.
| |
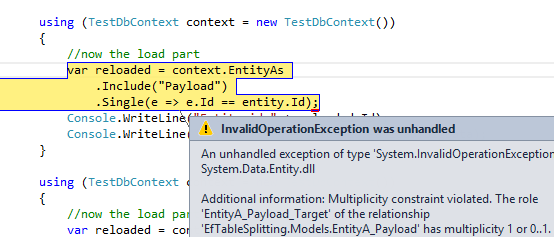
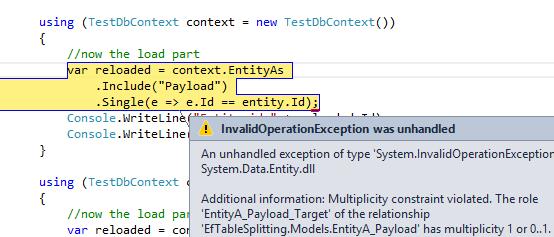
If you try to load EntityA with an include to Payload, you will get: Multiplicity constraint violated. The role ‘EntityA_Payload_Target’ of the relationship ‘EfTableSplitting.Models.EntityA_Payload’ has multiplicity 1 or 0..1.
{kind=link}
Figure 1: Error happens if you automatically initialize _payload in the constructor
Here is basically what happens inside EF: after issuing the query to the database, when he construct an instance of EntityA, it got the Payload property already populated with an Id of 0 and EF complains because he got different id from the database, so he is thinking that Entity2 refers two distinct PayloadEntity when the relation is 1:1 (they should share the very same id). This supposition is enforced because if you normally load an instance of EntityA, if you access Payload.BigData property it is always null. This happens because you are creating an empty instance of Payload in the constructor and EF does not populate Payload property with the Proxy object that will trigger lazy load.
This is usually a no-problem, because in DDD or more generally in OOP you should create Factory Methods to create entities in valid state. The best approach is make the constructor protected and create a factory method to create an instance in a valid state.
| |
Thanks to this code, usage of the class is really simplified, here is how you can create a couple of instances, one with payload and the other without payload.
| |
EF is able to use the protected constructor when it rebuild entities from database data, this will make everything working as usual. The usage of EntityA is simple, thanks to factory methods you should never worry of forgetting populating the Payload because it will happens automatically. Since all the properties are virtual, EF can enable Lazy load, and you are able to write the following code.
| |
If you use EfProfiler or a standard Sql profiler, you can verify that this piece of code actually issues two distinct queries to the database. The first one is used to load all properties of EntityA, and only if you access the Payload object LazyLoad will load the BigData for you. This approach is more complex of Nhibernate Lazy Properties, but it gives you the very same result: Lazy loading one or more columns of a table.
This is the first query issued by EF
| |
When you access the Payload property EF will issue another query to load properties mapped in the Payload.
| |
I find this approach really appealing because it explicitly suggest to the user of the Entity that the Payload is something that is somewhat separate from the standard entity. While Nhibernate property lazy loading is much more simpler to use (just declare the property lazy), it completely hides from the user of the entity what is happening behind the scenes. EF approach create a structure that is much clearer IMHO. Thanks to this clearer structure, a user can ask EF to eager-fetch the Payload if he knows in advance that the code will use it.
| |
You can in fact use the.Include as for any other navigation property, ignoring that the underling database structure actually stores everything in the same table. Here is generated query.
| |
This is where EF fails a little, because it generates the query as if the two entities would be mapped on different tables instead of issuing a standard query on the EntityA table. This is a minor issue, but I think that it should be addressed in future versions. The important aspect is that I’m able to load everything with a simple roundtrip to the database when needed.
My final conclusion is: Table Splitting in Entity Framework is a really good technique especially for legacy databases, where you cannot change the schema. Thanks to it, you can split columns of a single database table on two distinct entities, loading the less-used data only when needed. If you are not working with legacy database you should consider if a standard two tables approach is preferable , especially because you can also store the less-used table in other filegroup placed on slower disks. With the emerging trend of SSD, it is not uncommon to have server instances with 250 Gb of high Speed SSD and much more space on standard mechanical disks (much slower). Being able to decide where to place the data is a key factor in system where the speed is critical.
Gian Maria.