Continuous Delivery in Agile procedures
“The hardest single part of building a software system is deciding precisely what to build.”
**Frederick P. Brooks, The Mythical Man Month This simple sentence contains big truth, the process of building a software has many pitfalls, but the vast majorities of them are related to requirements and gaining a deep understanding of the real problem that the software is going to solve. To build a great software you need to be aware that the act of writing code is just a minimal part of the problem and mastering Application Lifecycle Management is the key of success **.
In these years Scrum emerged as a lead process to rationalize development. One of the key of its success is the ability to gather feedback early, to continuously steer your requirements (Backlog Items) because iteration after iteration you have a better comprehension of what needed to be build. If you want more detail on Scrum process you can read the Official Scrum Rulebook that will give you a good introduction over the process.
One of the key aspect is having a “potentially shippable product increments” at the end of each Sprint (time boxed interval of time). This maximize the visibility of the process, because at the end of each Sprint the progress the team will inspect what they have achieved and they can gather feedback from Product Owner and users. The key aspect is** “potentially shippable”, the increment produced during a sprint should be ready to be moved in production easily, and at least you should deploy in Test and/or pre-production Environments for Beta Testing **. One of the major risks of implementing Scrum or in general an iterative process is a “non potentially shippable” increment at the end of an iteration (I suggest you to read Software in 30 days).
The key aspect of Scrum is empiricism and transparency; you absolutely need to require that software is in Shippable State after an iteration. If this requirements is not met, Product Backlog Item from the Sprint Backlog will be moved again to the Product Backlog as “unfinished or Undone” to reflect the need of more work.
Scrum teams usually do demo at the end of the Sprint, to demonstrate what they achieved with the increment and** one of the most useful helps to have “potentially shippable software” is defining what exactly is a “demo”.**
This is just another aspect of Definition of Done, because doing a Demo of the sprint in a developer’s laptop can be acceptable, but it suffers from: It works on my machine syndrome. With modern software, the act of moving code from dev machine to production machines can be as simple as using Publish functionality of Visual Studio, or as complex as doing manual update of multiple environments (database, AT, Client code). In these days DevOps movement gains lots of popularity, and we are aware that all barriers between Dev (engineering) and Ops (Operations) should be removed as early as possible. The risk for the team is focusing only on Engineering side, forgetting that we need works to move and maintain code in production.
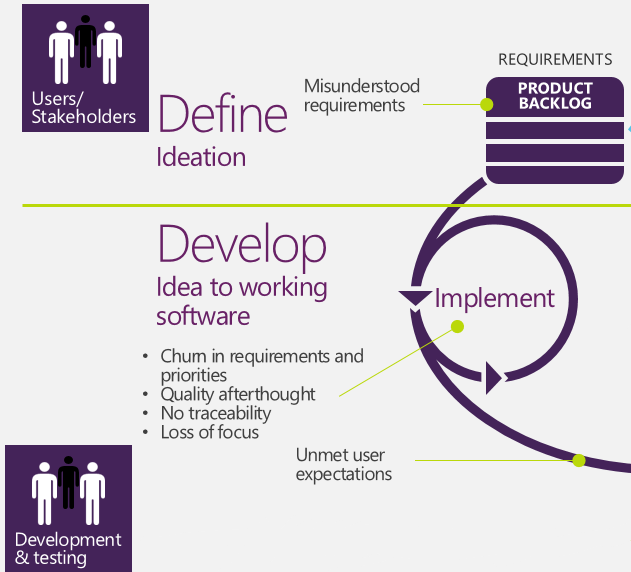
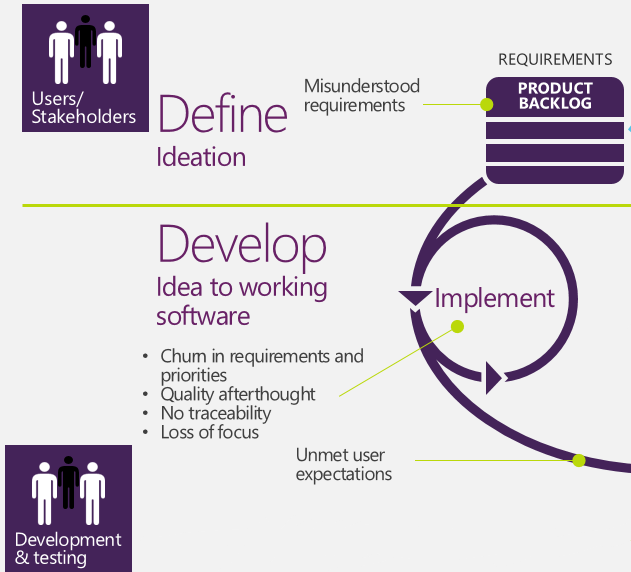
In the above picture most of the impediments that the team encounters towards the Goal of satisfying Product Owner and user are depicted. But this picture is incomplete, because it does not account for Operations related impediments.
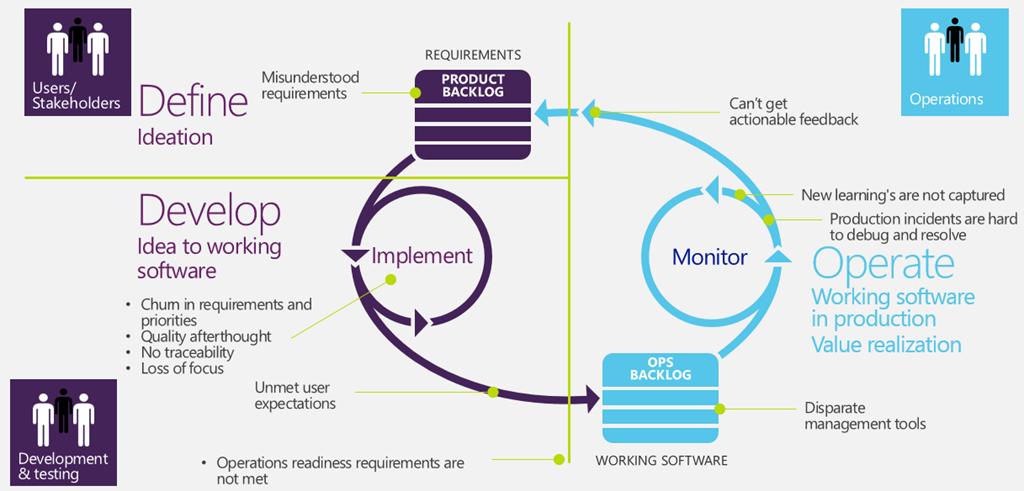
{kind=link}
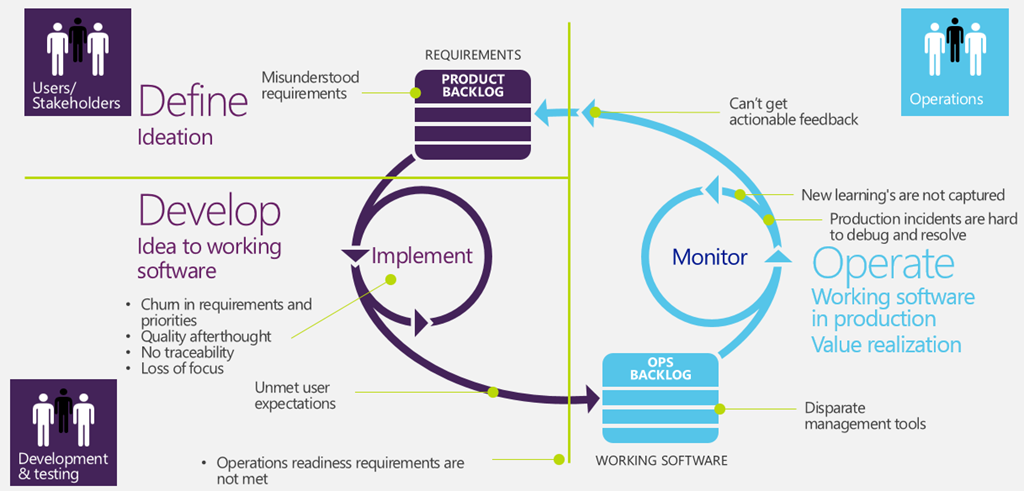{kind=link}
This is a more realistic situation, where another important impediment is: the increment produced in a Sprint does not met Operations Readiness requirements. Such impediments derives from many disparate reason; some related to technological problem (Sql database schema updates or in general change in schema of saved data) some other arise from poor communication between Dev and Ops (software configurations spread over multiple sources: web.config, database, etc without any documentation). Quite often developers simply underestimate the cost of a change. A modification that can be easy done on dev machine, can be much more complex or problematic in production environments (Ex. Big database in production, complex multi machine deployment, 99,999% uptime and so on).
Continuous delivery is one of the key procedures that helps you to guarantee that the software is always in a “shippable state”. It basically consists of automatic procedures that bring code changes from source control and deploy automatically to Test and production machines. The whole process can be automated or can require the press of a button, but it should not require more than this. Nothing is much frustrating that finishing a sprint and realize that there are some barriers that makes really difficult or even prevent the code to be deployed in Test or Production environments. One of the classical example is changing the structure of a Relational Database making it not compatible with other piece of the software developed by other teams.
Another risk of demo done in “developer computer” is that you have no way to verify if the increment is stable enough, or has problem once exercised in production-similar environments. Thanks to Continuous Deployment you can deploy on multiple environments, test upgrade with production data test lab and maintain one or more beta environments where beta tester can assure that the software is stable and meets QA requirements.
Here is some improvement you will gain if you start moving to Continuous Delivery
- No more deployment nightmare
- Detailed log of deploy steps
- Ability for dev to one-click deploy in test or preproduction environment to test with Real-Data
- Better repro and fix of bug in Production
- Ability to rollback a deploy
- Turn features on/off easily with feature flags.
- Early feedback from Products Owner / Stakeholders
- Easy maintenance of Beta Product
Having a Continuous Deployment architecture in place makes the team confident of being able to move iteration increments from dev machine to shared environments. Team Foundation Server helps a lot with Lab Management that permits you to manage environments and automatically run workflow of Build-Apply baseline snapshot-Deploy on Virtual machines. With TFS 2013 Microsoft acquired in-release to give you a more complete solution to manage workflows to bring code from TFS to production Server.
Moving product increments automatically from dev machines to a chain of environments (test, pre-production, production) and maintaining them is a key part of the whole iterative process and helps the team maintaining high software quality.
Gian Maria.