Import folder of documents with Apache Solr 40 and tika
In a previous article I showed how simple is to import data from a Sql database into Solr with a Data Import Handler, in this article I’ll use a similar technique to import documents stored inside a folder.
This feature is exposed by the integration with Tika, an open source document analyzer capable of extracting text by various formats of files. Thanks to this library solr is capable of crawling an entire directory, indexing every document inside it with really minimal configuration. Apache Tika is a standalone project, you can find all supported formats here and you can use directly from your java (or.NET code) but thanks to Solr Integration setting everything up is a real breeze.
First of all you need to copy all required jars from solr distribuzion inside lib subdirectory of your core, I strongly suggest you to grab all the files inside contrib\extraction\lib subdirectory of solr distribution and copy all of them inside your core, in this way you can use every Data Import Handler you want without incurring in errors because a library is not available.
To import all files you can simply configure an import handler as I described in the previous article, here is the full configuration
| |
This is a really simple import configuration but there are some key point you should be aware of.
All of my schema.xml have a unique field called id, that serves me as a purpose of identifying the document , and is the key used by solr to understand if a document should be inserted or updated. This importer uses a BinFiledataSource that simply crawl inside a directory looking for files , and extracting standard values as Name of the file, last modify date and so on, but it does not know the text inside the file. This dataSource has a document entity called files, and has a rootEntity=”false” because this is not the real root entity that will be used to index the document. Other attributes simply states the folder to crawl, document extension to index and so on.
In that entity you find columns related to file attributes and I’ve decided to include in the document three of them
- fileAbsolutePath that will be used as unique index of the document*
- fileSize that contains the size of the file in bytes*
- fileLastModified that contains the date of last modification of the document*
After these three fields there is another entity, based on TikaEntityProcessor, that will extract both text and metadata from the document. This entity is the real entity that will be indexed and it is the one that use Tika library to extract all information from documents, not only file related one. It basically extract all the text plus all file metadata attribute if presents. Here is the list of the field I want to store inside my index
- file: contains files name (opposed to the id field that contains the full path of the file)*
- Author and Title: both are metadata of the document, and they are extracted by Tika if present in the files*
- text: that contains the text of the document.*
Clearly you should define all of these field accordingly inside your schema.xml file.
| |
This is all you need to do, really!!. You can now toss some documents inside specified folder, then go to solr console and try to execute the import.
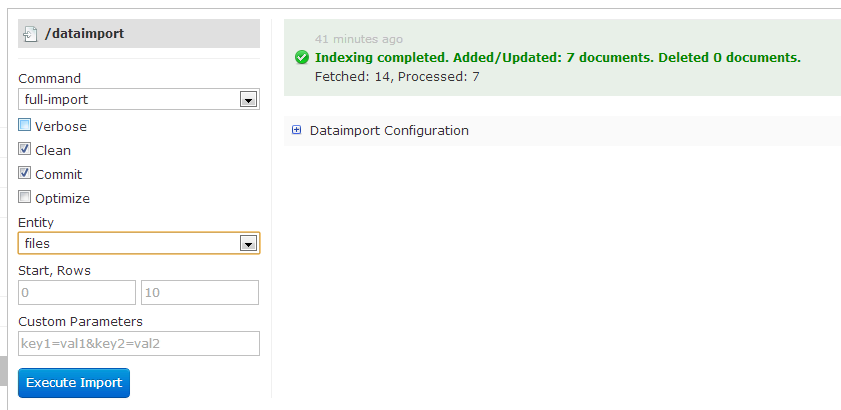
Figure 1: Importing documents from Solr Web UI
If you have error during the import process, please refer to solr logs to understand what went wrong. The most obvious problem are: missing jar file from the lib directory, document missing some mandatory fields specified in schema.xml (such as missing id).
Now you can query and look at what is contained inside your index.
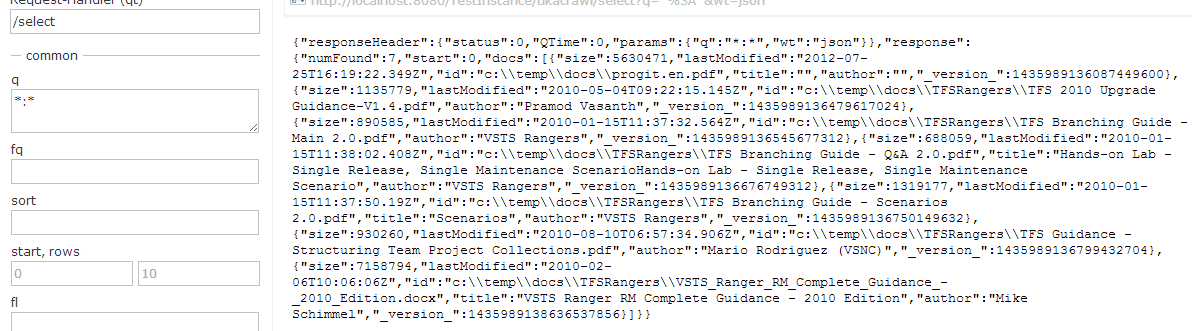
figure 2: A standard catch all query to verify what is inside your index
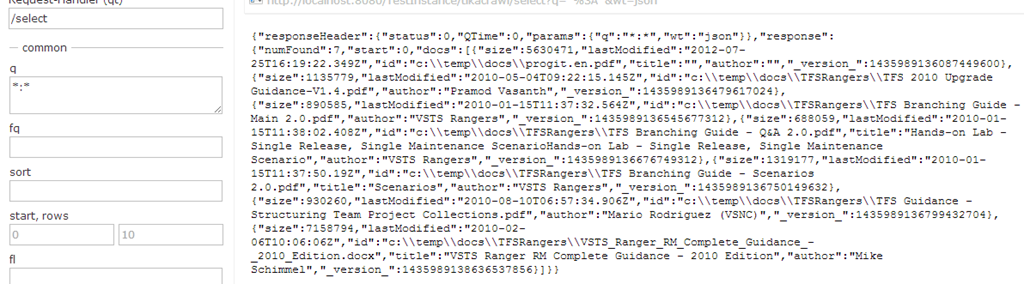
One of the cool feature of tika is extracting metadata and text from your files, as an example you can search for text that contains the word “rebase” with the query text:rebase

{kind=link}
{kind=link}
{kind=link}
Figure 3: Return of a search inside the text of the document
As you can see, it founds progit.en.pdf book, and if you look at the properties you can find that this book does not contains nor author or title metadata, because they are missing in the original document. Since those fields are not mandatory, if they are not present in the file, nothing bad happens, but you are still able to search inside original text of the pdf file.
Gian Maria