I have a domain where one of the business operation consists of analysis of some entities, for each entity we need to do complex analysis involving external servers and until now we could live with a single server that sequentially analyze those entities one after another.
All works good, but we reach a point where the amount of work reached the capacity of the Analyzer server, so we need to change the analysis algorithm to parallelize the analysis.
Simply launching the analyzer application on multiple server produces errors, because analyzing a single entities it is a work of several seconds, and there is high chance that both server start to analyze the very same entity. The Analyze operation is idempotent, so there is no problem in data if two server analyzes at the same data at the same moment, but we have timeout problem due to lock in database (the result of analysis was kept in ram, but when it finished it simply open a transaction, clear old result, and insert all new data). I need some way to make the two analysis independent one from each other.
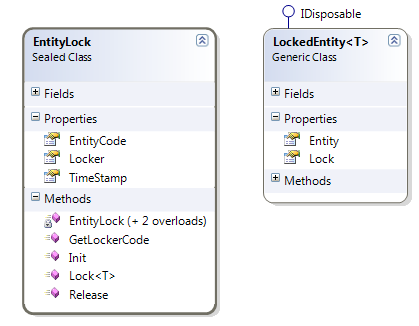
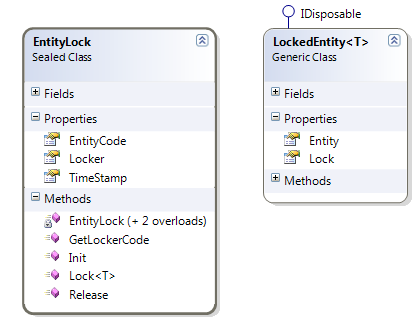
I introduced in the domain the concept of EntityLock and LockedEntity
{kind=link}
{kind=link}
{kind=link}
Figure 1: Schema of EntityLock and LockedEntity
I simply need some mechanism to tell I want to modify this entity and I want to be sure that no other machine or process is actually using it. The class has three properties, one is EntityCode and is the logical Id of the entity being modified, Locker field contains a code that identify the process that settled the lock (actually is machineName + full path of the executable) and finally the timestamp identify the date and time when the lock was imposed.
Since I need to share the lock between multiple machines I can simplify the design using the Database as the backing storage for the locks.
| |
The lock function accepts a logical id and the entity that should be locked. I could pass only the entity if I have some base entity, but my domain is on a legacy database, I have entity with GUID id, some other with Int32 IDENTITY, so I need to specify the id with a string. When the entity have guid Id I can use the Id, if it has a Identity ID I use id + entityname, and so on. Since the logical Id is the primary key (generator assigned) of the EntityLock, I simply try to insert a new EntityLock in database and if some other component had already locked that same entity an exception of Primary Key violation will occur (I could even obtain better performance doing a lookup before the insertion, but I need to acquire a lock each several minutes I do not care about performances). When an exception is raised I simply return null, meaning that the entity could not be locked, if the insert operation was successful I return the entity wrapped in a LockedEntity<T> class, that simply implement IDisposable because it release the lock when it got disposed.
![]()
With this class each analyzer server ask for the next data to analyze, try to lock it, and if the lock failed, it ask for another data until he find a data object that can lock or there is no data to analyze. All the analysis operation are done inside a using, so the lock on the entity got disposed as soon the analysis finish.
alk.
Tags: Nhibernate