One of the reason why people do not write tests, is that some code is difficult to test, and one of the main reason for this difficulty is coupling. The obvious solution is to write loosely coupled code from the beginning, but if you are working with legacy code this option is not applicable.
The problem is that if you have no test and the code is difficult to test you avoid to refactor; after all, if everything works as expected, why you should introduce bug with refactoring? The reason is that sometimes technical debt is so high, that code is unmanteniable, and you are forced to refactor.
One of the worst piece of code to test is the following one.

ResultdatabaseInserter is a static class that takes a block of data and perform massive insert/update/delete operation on a database with millions of records. The problem is not what the method to, but the fact that it is static.
The InsertData method has about 60 unit tests that verify that the complex massive operation are good, but it is used in some core section of the software. If the class XX uses InsertData static method to save the result of data elaboration you are in trouble, because usually you use the four phase test.
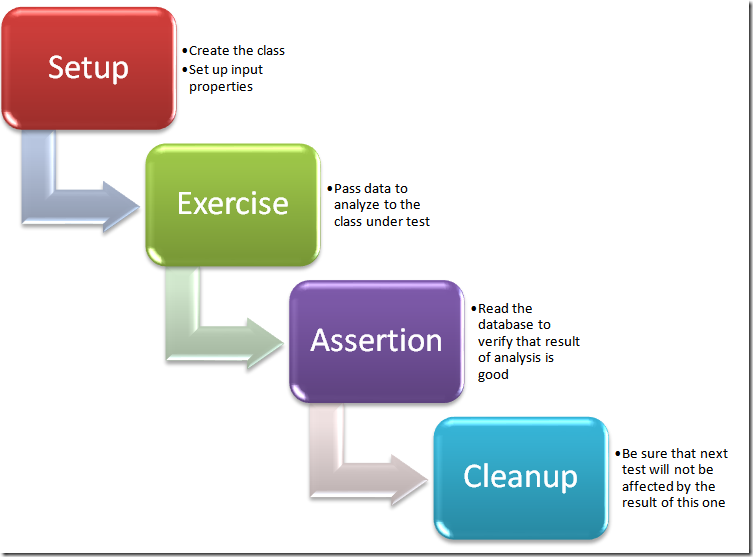
If you start writing code that makes assertion on data in DB you surely will find problems. The first operation I usually do in this scenario is making the ResultdatabaseInserter class not static, convert the InsertData method to a virtual one , and change every part of the code where you call the function, because it is not static anymore. To simplify the process I create a public property in every object that uses InsertData function.
{kind=link}
{kind=link}
{kind=link}
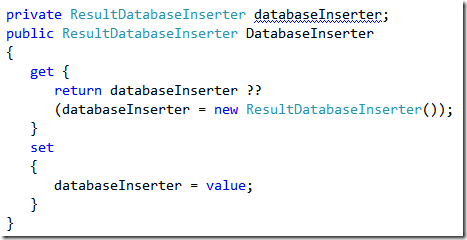
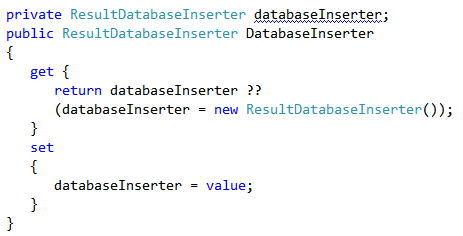
The advantage of this approach is clear: first of all I do not modify the behavior of the code, because I did not modify code in the InsertData method, and then with lazy creation I’m able to get rid of initialization problem, if no one populate the DatabaseInserter property, the object simply creates an instance of the default inserter.
This modification did not introduce bugs, because I actually did not change the code, but now with this little modification I’m able to write this function in a fixture.
| |
This function uses the AutoMockingContainer helper class that create a mock for every dependencies of the original class. The result is a new instance of SutClass where every dependency is resolved by a Mock (thanks to RhinoMock) Now my test code look like this.
| |
I omitted the setup part, where I mock repository and create parameter to be passed to SUT; the real important stuff is in line 4, where I retrieve the argument passed to the InsertData function of my Mocked ResultDatabaseInserter and make assertion on it. With this little refactoring I’m able to completely avoid a call to the database, and thanks to Rhino Mock I’m able to setup assertion on parameter passed to any mock.
This is a standard example on how to refactor your code and use a Test Double to make testing simpler.
Alk.