Scenario: you have a software where you have a standard search made in UI for data in a board, then you need to move the search server side (due to the increasing number of object in the board), so you switch to ElasticSearch to have nice full text functionalities. Then you have an exact request: Does ElasticSearch supports searching with Unicode chars? The answer is yes, but then you find that users complains about not being able to search with Unicode chars.
The problem is that Unicode is a really complex standard, it is not just an Extended ASCII sets, it is really more. If you work with ElasticSearch you should already know that you need to have a better understanding of Unicode in turn to handle some specific requests. I suppose that you know how elastic works, but for a quick reminder, when you feed text into a field of a document in ES text is splitted into tokens with specific algorithms that are called analyzers, then you can search for those tokens.
In my specific problem the users (that are always creative) use some special Unicode chars to categorize the card in the software, like char 💥 Collision symbol and others. Then when they search for that symbol, nothing is found. When you have this situation you need to fire your tool of choice to perform REST request and verify how analyzer works. In my situation text is indexed with standard analyzer, so you need to understand how ES treat your specific piece of text.
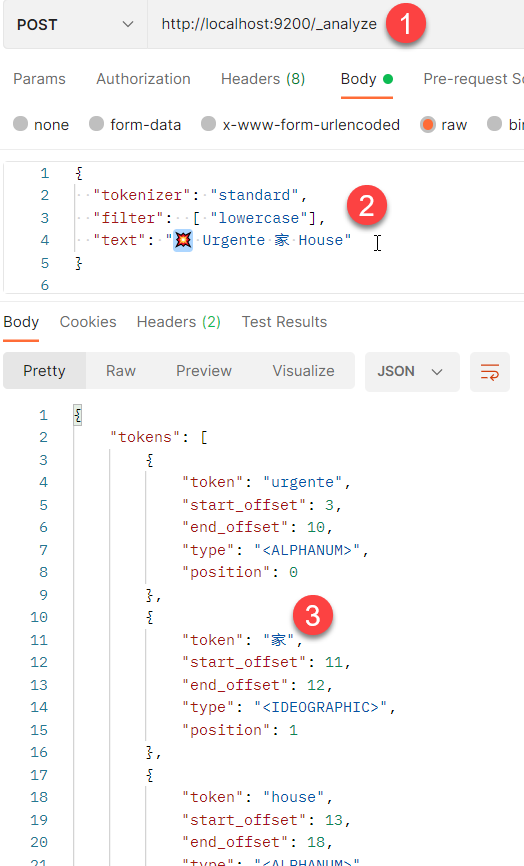
Figure 1: Elasticsearch analyzer test with Postman.
As you can verify from Figure 1 when you pass Collision symbol into the analyzer, it got removed from the output. This happens because if you look in unicode table for Collision Symbol, it has a category of Symbols-other and ES consider it not to be interesting text to search. Kanji is maintained because it is valid japanese text where a user is supposed to search. The standard analyzer is made to keep only tokens that can be interesting to search in a textual search, so a symbol is not considered interesting text to search and then it is stripped away from the process.
If you think this is weird, try to feed the string “se:parator se;parator se/parator” into standard analyzer to verify generated tokens, you can be surprised that the result is: [se:parator, se, parator, se, parator]. A question arise, if the standard tokenizer is trying to identify single words, it is clear that se;parator is splitted in two token (“se” and “parator”), but why se:parator is not splitted in two tokens? If you follow Official Documentation you see that the link refers to an official documentation called Unicode® Standard Annex #29 where you can undersand that : char is not considered a separator.
Elasticsearch is a complex beast, you need to know how various analyzers work to be able to satisfy user need
If you take the request made in Figure 1 and change the tokenizer to “whitespace” you can verify that it seems to resolve the problem because it splits token with whitespace only, so your weird symbol Unicode chars are preserved. This does not solve another problem, what about the user not putting a space between symbol and the next word?.
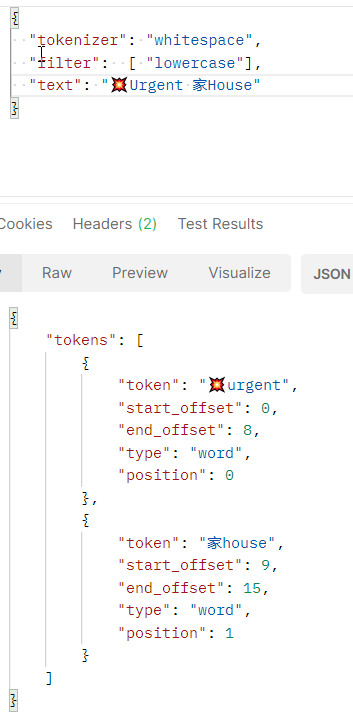
Figure 2: Whitespace analyzer in action.
The situation is even worse, because now even the kanji is not splitted from the subsequent word if you forget to put a space. This is bad because now the user can search for Collision unicode char, but it found a result only if it is surrounded by space. This will lead to the classic question: Why searching for this char does returns document 1 but not document 2?
The solution is create a custom analyzer, when you create the index you issue a PUT request to http://localhost:9200/nameoftheindex with this payload
| |
Actually there are lots of things going on on that mapping. First of all I have defined a custom tokenizer called my_tokenizer that is using a pattern to split the input string into tokens. This can use java regular expressions to split the string, with standard configuration it will split on match of regular expressions. The Group = -1 means that we are not interested in capturing matching group, on the contrary we want to split token based on matches. This means that we need to specify the regex that identify splitting characters.
Default value for pattern is \W+ that basically means: split on any non word character. You can consult a table here with the various supported identifiers. Now you can see that I’ve used a really different pattern: (?<=[^\p{ASCII}]|\s) so let break it in basic components.
First of all syntax (?<=…) is a lookbehind assertion, it allows me to split for a pattern, but also to capture splitted characters. The pattern is simple, the part ^\p{ASCII} means: split on any character that is not in the ASCII set. The part \s means: a whitespace. The full expression means: split on any character that is not in the ASCII set or a whitespace and keep that character.
The (<= … ) syntax in java regex allows me to choose splitting patterns but at the very same time keep them in the result.
The game is, I want to split for any char that is a space (like the whitespace analyzer) but also split each time I encouter a NON ASCII character, but since I’m interested in not losing Unicode characters I need to keep them in the result.
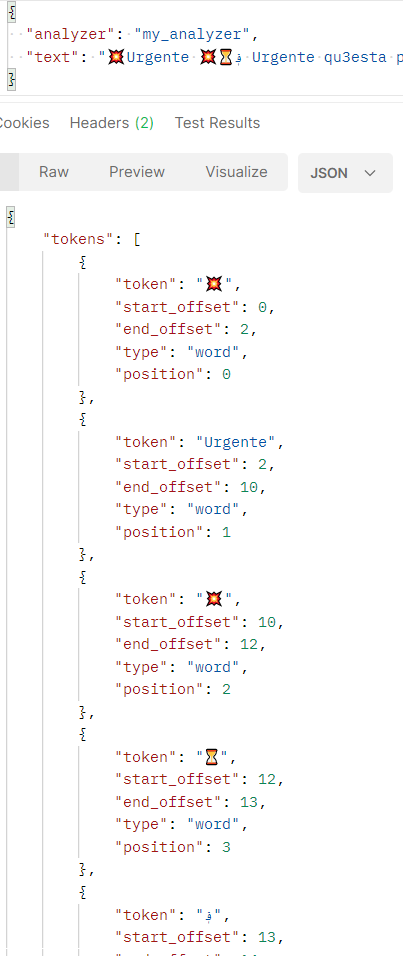
Figure 3: Pattern tokenizer in action.
As you can see in Figure 3, with this new analyzer each non ASCII caracter is kept in the result as a single token so you can find with a standard search. As always ElasticSearch is an amazing tool that can be configured to solve your specific needs.
Gian Maria.